How I Improved My Paintings Recommender Web App
Overview
I wanted to build something like "Tinder for paintings" - a way to discover art that matches your taste. The idea started when I found a dataset of around 37,000 paintings from various museums and collections. Instead of scrolling through endless galleries, why not let users swipe through paintings and learn their preferences?
The Web App Idea
The concept is straightforward: users browse through paintings one at a time, liking or skipping each one. Based on their likes, the app recommends similar paintings they might enjoy. It's a simple interaction model that makes art discovery feel more personal and engaging.
Initial Design Issues
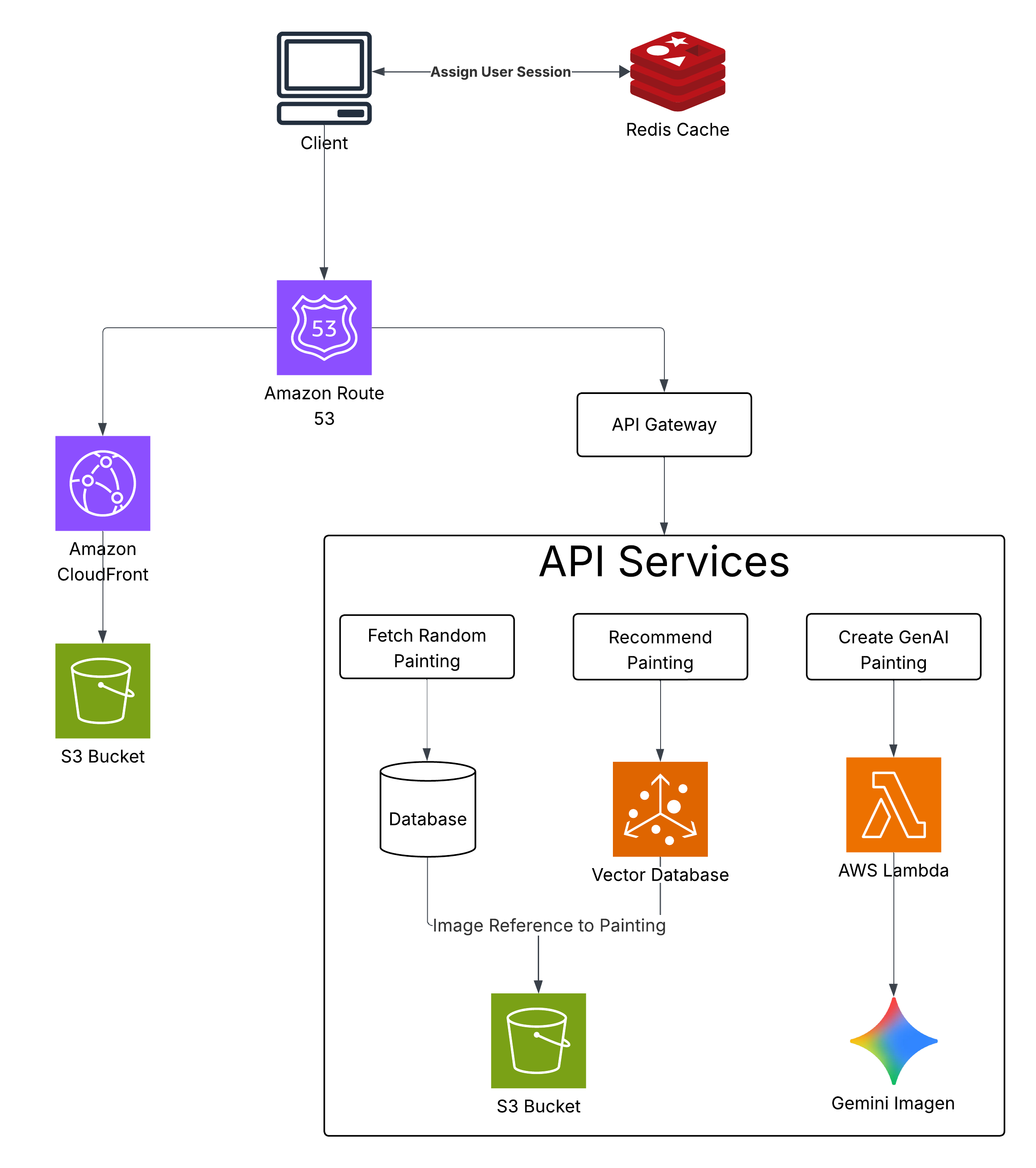
My first implementation had some significant problems. I was storing everything in MongoDB, which limited me to only about 4,000 paintings due to storage constraints. The image fetching was painfully slow - each painting took several seconds to load because I was pulling directly from the original sources.
Performance Improvements
To fix the loading issues, I moved all the painting images to AWS S3 with transfer acceleration enabled. This dramatically improved load times. I also added Redis caching with a 1-week TTL for frequently accessed paintings, which reduced database queries and made the browsing experience much smoother.
Recommendation System
For recommendations, I built a vector similarity search using ChromaDB. Each painting gets embedded using OpenAI's text-embedding-3-small model, producing 1536-dimensional vectors. When a user likes paintings, I find similar ones using cosine similarity. This approach captures both visual and contextual similarities based on the painting metadata.
AI Enhancement
I added a feature using Google's Imagen model to generate new paintings based on a user's preferences. After analyzing what styles, colors, and subjects a user tends to like, the system can create original artwork that matches their taste. It's an experimental feature but adds an interesting creative element to the app.
Deployment Architecture
The final architecture runs on AWS EC2 with both Node.js (for the web server) and Python (for the ML components). Image generation is handled separately through AWS Lambda to keep costs manageable - it only runs when users explicitly request generated artwork.